Technology Basics¶
What does yap do¶
All sequencing technologies are methylation based¶
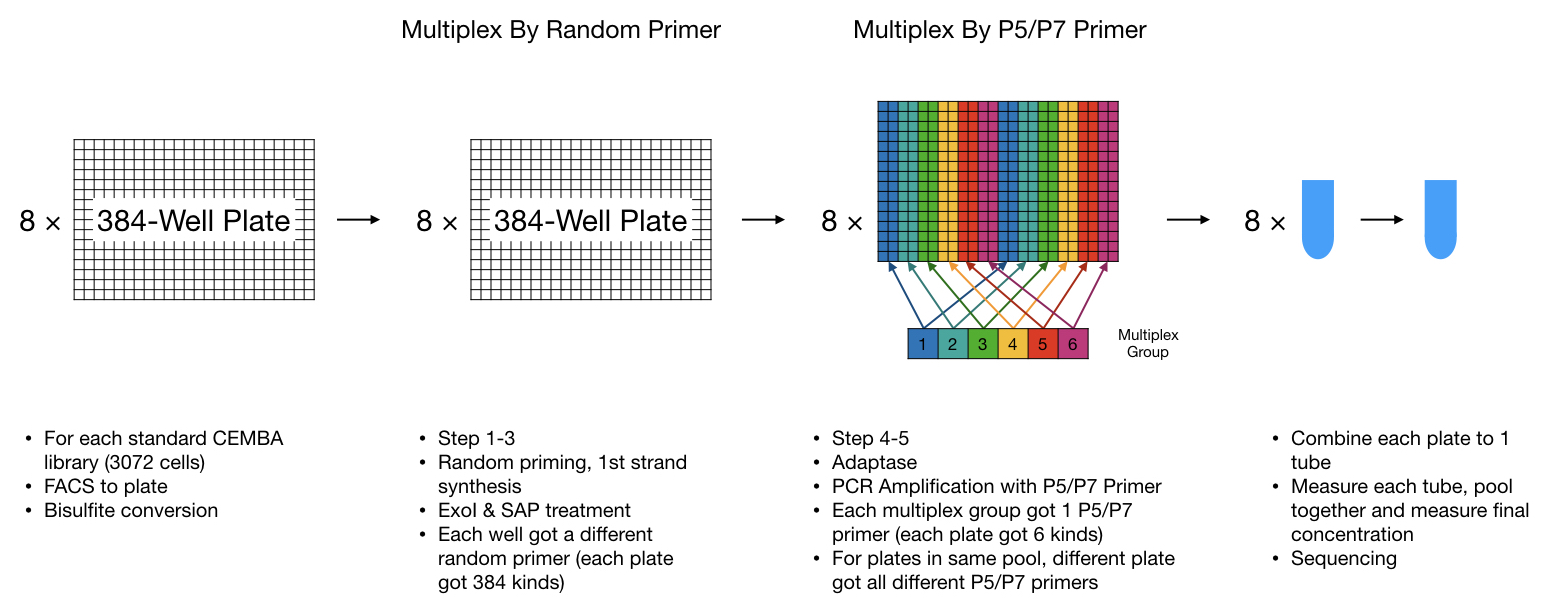
All the technologies covered by yap is based on snmC-seq2, here I visualized the steps and barcoding strategies we used currently in Ecker Lab for snmC-seq2. This is basically all yap mapping is based on.
Multiplex cell in preparing library¶
When preparing library, the most important part related to mapping is the cell multiplexing:
use random primer (inside pipeline, index_name corresponding to each random primer)
use illumina P5/P7 primer pair (inside pipeline, primer_name and uid corresponding to each illumina P5/P7 primer pair)
Demultiplex cell in mapping¶
When mapping use yap (notice the reverse order):
prepare samplesheet for bcl2fastq, use bcl2fastq to demultiplex illumina P5/P7 primer pair. Each result file set got a uid, that uid corresponding to the illumina primer pair throughout the pipeline.
use cutadapt to demultiplex random primer. Each result file set got a index_name, that index_name corresponding to the random primer throughout the pipeline.
uid + index_name uniquely determine a cell within the same pool on MiSeq or NovaSeq.
After getting single cell files, yap just do mapping steps for each individual cells, and then summarize all the mapping stats for the whole library.
Important Reference¶
snmC-seq2 Library¶
Molecular steps¶

Reads and Primer Structure¶

Cell Multiplexing¶
V1 (8-random-index)¶
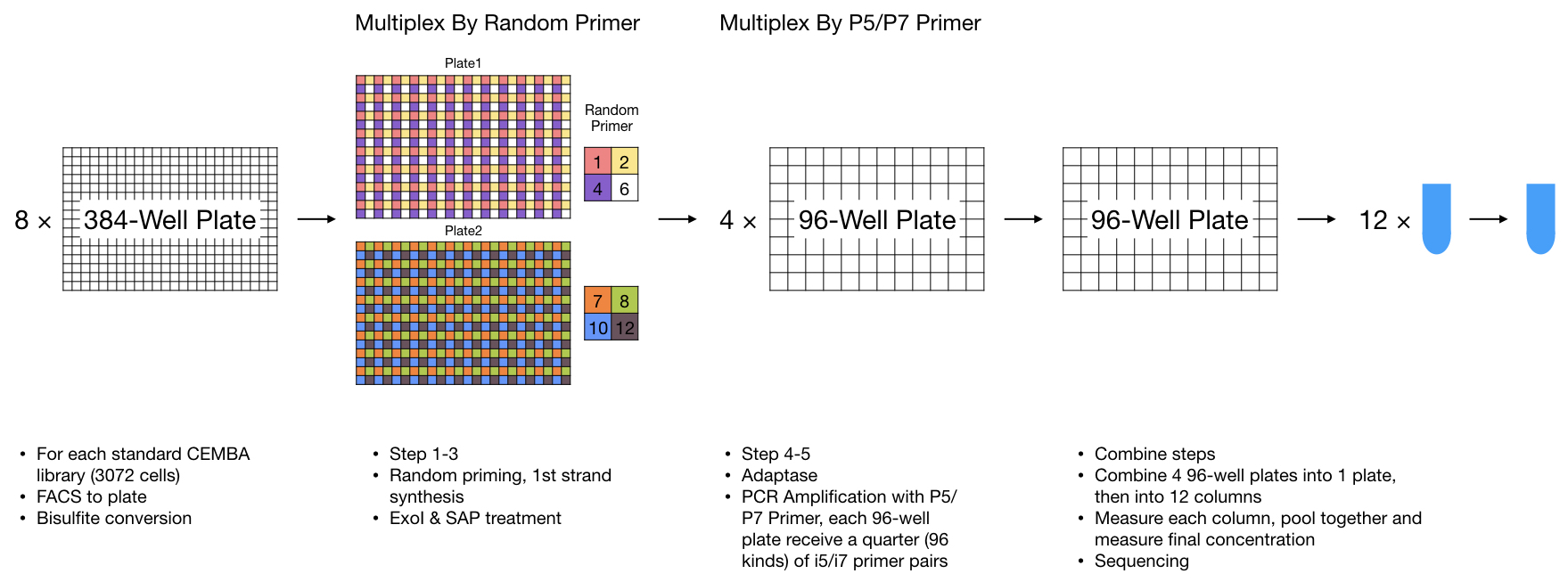
V2 (384-random-index)¶